
Top 100+ Machine Learning Interview Questions Answers PDF
What is the definition of learning from experience for a computer program?
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.

Explain what is Machine learning?
Machine learning is the field of study that gives computers the avility to learn without being explicitly programmed.
OR
The acquisition of knowledge or skills through study or experience by a machine.
OR
The ability for machines to learn without being explicitly programmed.

What are different types of learning?




Artificial Intelligence: artificial intelligence. As the name implies, it means to produce intelligence in artificial ways, in other words, using computers.


Machine Learning: This is a sub-topic of AI. As learning is one of the many functionalities of an intelligent system, machine learning is one of the many functionalities in an AI.
Deep learning: Deep learning is the specific sub-field in machine learning involving making very large and deep (i.e. many layers of neurons) neural networks to solve specific problems. It is the current “model of choice” for many machine learning applications.
What are some popular algorithms of Machine Learning?
Decision Trees
Neural Networks (back propagation)
Probabilistic networks
Nearest Neighbor
Support vector machines(SVM)
What are the three most important components of every machine learning algorithm?
Representation: How to represent knowledge. Examples include decision trees, sets of rules, instances, graphical models, neural networks, support vector machines, model ensembles and others.
Evaluation: The way to evaluate candidate programs (hypotheses). Examples include accuracy, prediction and recall, squared error, likelihood, posterior probability, cost, margin, entropy k-L divergence and others.
Optimization: The way candidate programs are generated known as the search process. For example combinatorial optimization, convex optimization, constrained optimization.
Explain Supervised learing?
In unsupervised learning we only have xi values, and also have explicit target labels.

Explain Unsupervised learing?
In unsupervised learning we only have xi values, but no explicit target labels.
Difference between Supervised and Unsupervised learning?
What type of algorithm used in Supervised and Unsupervised learning?

Explain classification?
In machine learning, classification is the problem of identifying to which of a set of categories (sub-populations) a new observation belongs, on the basis of a training set of data containing observations (or instances) whose category membership is known.
What is reinforcement Learning?
The goal is to develop a system (agent) that improves its performance based on interactions with the environment. Since the information about the current state of the environment typically also includes a so-called reward signal, we can think of reinforcement learning as a field related to supervised learning. However, in reinforcement learning this feedback is not the correct ground truth label or value, but a measure of how well the action was measured by a reward function. Through the interaction with the environment, an agent can then use reinforcement learning to learn a series of actions that maximizes this reward via an exploratory trial-and-error approach or deliberative planning. A popular example of reinforcement learning is a chess engine.
Describe the relationship between all types of machine learning and particularly the application of unsupervised.
In supervised learning, we know the right answer beforehand when we train our model, and in reinforcement learning, we define a measure of reward for particular actions by the agent. In unsupervised learning, however, we are dealing with unlabeled data or data of unknown structure. Using unsupervised learning techniques, we are able to explore the structure of our data to extract meaningful information without the guidance of a known outcome variable or reward function.
What do you understand by Cost Function in supervised learning problem? How it help you?
Cost function takes an average difference of all the results of the hypothesis with inputs from x's and the actual output y's. and help to figure best straight line to our data.

What is a support vector machine?
Maximize the minimum distance of all errors.
e.g.
The dish is good by itself but to enhance the dish, you put the most amount of salt in a dish without it tasting too salty
What do we call a learning problem, if the target variable is continuous?
When the target variable that we're trying to predict is continuous, the learning problem is also called a regression problem.
What do we call a learning problem, if the target variable can take on only a small number of values?
When y can take on only a small number of discrete values, the learning problem is also called a classification problem.
Explain classifiers?

What do you understand by hypothesis space?
It is a set of legal hypothesis.

How do we measure the accuracy of a hypothesis function?
We measure the accuracy by using a cost function, usually denoted by J.
Describe variance and bias in what they measure?
Variance measures the consistency (or variability) of the model prediction for a particular sample instance if we would retrain the model multiple times, for example, on different subsets of the training dataset. We can say that the model is sensitive to the randomness in the training data. In contrast, bias measures how far off the predictions are from the correct values in general if we rebuild the model multiple times on different training datasets, bias is the measure of the systematic error that is not due to randomness.
Describe the benefits of regularization?
One way of finding a good bias-variance tradeoff is to tune the complexity of the model via regularization. Regularization is a very useful method to handle collinearity (high correlation among features), filter out noise from data, and eventually prevent overfitting. The concept behind regularization is to introduce additional information (bias) to penalize extreme parameter weights.
Explain Random forest?
Random forest is a collection of trees, hence the name 'forest'! Each tree is built from a sample of the data. The output of a RF is the model of the classes (for classification) or the mean prediction (for regression) of the individual trees.
What are training algorithms in Machine learning?
Training algorithms gives a model h with Solution Space S and a training set {X,Y}, a learning algorithm finds the solution that minimizes the cost function J(S)
Explain Training and Testing phase in Machine learning?

Explain Local minima?
The smallest value of the function. But it might not be the only one.
What is multivariate linear regression?
Linear regression with multiple variables.
How can we speed up gradient descent?
We can speed up gradient descent by having each of our input values in roughly the same range.
What is the decision boundary given a logistic function?
The decision boundary is the line that separates the area where y = 0 and where y = 1. It is created by our hypothesis function.
What is underfitting? p
Underfitting, or high bias, is when the form of our hypothesis function h maps poorly to the trend of the data.
What usually causes underfitting?
It is usually caused by a function that is too simple or uses too few features.
What is overfitting? p
Overfitting, or high variance, is caused by a hypothesis function that fits the available data but does not generalize well to predict new data.
What usually causes overfitting?
It is usually caused by a complicated function that creates a lot of unnecessary curves and angles unrelated to the data.
How can we avoid overfitting?
Stop growing when data split is no more statistically significant OR grow tree & post-prune.
What is features scaling?
Feature scaling is a method used to standardize the range of independent variables or features of data. In data processing, it is also known as data normalization and is generally performed during the data preprocessing step.
What are the advantages of data normalization?
Few advantages of normalizing the data are as follows:
1. It makes your training faster.
2. It prevents you from getting stuck in local optima.
3. It gives you a better error surface shape.
4. Wweight decay and bayes optimization can be done more conveniently.
What range is used for feature scaling
0-1
What is the formula for feature scaling?
(x-xmin)/(xmax-xmin)
What two algorithms does features scaling help with?
K-means and SVM RBF Kernal
What two algorithms does features scaling NOT help with?
Linear regression and decision trees
What do you understand by clustering?
Clustering means grouping of data or dividing a large data set into smaller data sets of some similarity.
What is a good clustering algorithm?
K-means
In a basic sense, what are neurons?
Neurons are basically computational units that take inputs, called dendrites, as electrical inputs, called "spikes", that are channeled to outputs , called axons.
What is a neural network?
Takes an input layer -> hidden layer of logistic regression -> outputs of the hidden layer are binary that go to the output layer
e.g.
is that a house cat? input layer is whiskers, fur, paws, large. Hidden layer finds that cats are small (so the output of the hidden layer is 1, 1, 1 ,0). Because not all features (outputs) from the hidden layers are true, it's not a house cat.
What is Regression Analysis?
We are given a number of predictor (explanatory) variables and a continuous response variable (outcome), and we try to find a relationship between those variables that allows us to predict an outcome.
What are the dendrites in the model of neural networks?
In our model, our dendrites are like the input features.
What are the axons in the model of neural networks?
In our model, the axons are the results of our hypothesis function.
What is the bias unit of a neural network?
The input node x0 is sometimes called the "bias unit." It is always equal to 1.
What are the weights of a neural network?
Using the logistic function, our "theta" parameters are sometimes called "weights".
What is the activation function of a neural network?
The logistic function (as in classification) is also called a sigmoid (logistic) activation function.
How do we label the hidden layers of a neural network?
We label these intermediate or hidden layer nodes. The nodes are also called activation units.
What is the kernal method?
When you can't use logistical regression because there isn't a clear delineation between the two groups, you need to draw a curved line. Multiply x & y to separate groups on a 3d plane.
e.g.
monkey in the middle. If there are two people on either side of the person in the middle, how do you draw a straight line to separate the two groups (e.g. logistical regression)? You can't. You have to draw a curved line.
What's the motivation for the kernel trick?
To solve a nonlinear problem using an SVM, we transform the training data onto a higher dimensional feature space via a mapping function and train a linear SVM model to classify the data in this new feature space. Then we can use the same mapping function. to transform new, unseen data to classify it using the linear SVM model.
However, one problem with this mapping approach is that the construction of the new features is computationally very expensive, especially if we are dealing with high-dimensional data. This is where the so-called kernel trick comes into play
Give the setup of using a neural network.
• Pick a network architecture.
• Choose the layout of your neural network.
• Number of input units; dimension of features x i.
• Number of output units; number of classes.
• Number of hidden units per layer; usually more the better.
How does one train a neural network?
1. Randomly initialize the weights.
2. Implement forward propagation.
3. Implement the cost function.
4. Implement backpropagation.
5. Use gradient checking to confirm that your backpropagation works.
6. Use gradient descent to minimize the cost function with the weights in theta.
How can we break down our decision process deciding what to do next?
• Getting more training examples: Fixes high variance.
• Trying smaller sets of features: Fixes high variance.
• Adding features: Fixes high bias.
• Adding polynomial features: Fixes high bias.
• Decreasing lambda: Fixes high bias.
• Increasing lambda: Fixes high variance.
What issue poses a neural network with fewer parameters?
A neural network with fewer parameters is prone to underfitting.
What issue poses a neural network with more parameters?
A large neural network with more parameters is prone to overfitting.
What is the relationship between the degree of the polynomial d and the underfitting or overfitting of our hypothesis?
• High bias (underfitting): both J train(Θ) and J CV(Θ) will be high. Also, J CV(Θ) is approximately equal to J train(Θ).
• High variance (overfitting): J train(Θ) will be low and J CV(Θ) will be much greater than J train(Θ).
Describe Logistic Regression vs SVM.
In practical classification tasks, linear logistic regression and linear SVMs often yield very similar results. Logistic regression tries to maximize the conditional likelihoods of the training data, which makes it more prone to outliers than SVMs. The SVMs mostly care about the points that are closest to the decision boundary (support vectors). On the other hand, logistic regression has the advantage that it is a simpler model that can be implemented more easily. Furthermore, logistic regression models can be easily updated, which is attractive when working with streaming data.
Give an overview of the decision tree process.
We start at the tree root and split the data on the feature that results in the largest information gain (IG). In an iterative process, we can then repeat this splitting procedure at each child node until the leaves are pure. This means that the samples at each node all belong to the same class.
Describe parametric vs nonparametric models?
Machine learning algorithms can be grouped into parametric and nonparametric models. Using parametric models, we estimate parameters from the training dataset to learn a function that can classify new data points without requiring the original training dataset anymore. Typical examples of parametric models are the perceptron, logistic regression, and the linear SVM. In contrast, nonparametric models can't be characterized by a fixed set of parameters, and the number of parameters grows with the training data. Two examples of nonparametric models that we have seen so far are the decision tree classifier/random forest and the kernel SVM.
What is feature extraction?
A method to transform or project the data onto a new feature space. In the context of dimensionality reduction, feature extraction can be understood as an approach to data compression with the goal of maintaining most of the relevant information.
Explain PCA in a nutshell.
It aims to find the directions of maximum variance in high-dimensional data and projects it onto a new subspace with equal or fewer dimensions that the original one. The orthogonal axes (principal components) of the new subspace can be interpreted as the directions of maximum variance given the constraint that the new feature axes are orthogonal to each other
What is Exploratory Data Analysis?
(EDA) is an important and recommended first step prior to the training of a machine learning model. For example, it may help us to visually detect the presence of outliers, the distribution of the data, and the relationships between features.
What is word stemming?
The process of transforming a word into its root form that allows us to map related words to the same stem
What is OLS?
Ordinary Least Squares (OLS) method is to estimate the parameters of the regression line that minimizes the sum of the squared vertical distances (residuals or errors) to the sample points.
What are residual plots?
Since our model uses multiple explanatory variables, we can't visualize the linear regression line (or hyperplane to be precise) in a two-dimensional plot, but we can plot the residuals (the differences or vertical distances between the actual and predicted values) versus the predicted values to diagnose our regression model. Those residual plots are a commonly used graphical analysis for diagnosing regression models to detect non-linearity and outliers, and to check if the errors are randomly distributed.
What is the elbow method?
A graphical technique to estimate the optimal number of clusters k for a given task. Intuitively, we can say that, if k increases, the distortion (within-cluster SSE) will decrease. This is because the samples will be closer to the centroids they are assigned to. The idea behind the elbow method is to identify the value of k where the distortion begins to increase most rapidly,
The two main approaches to hierarchical clustering are?
Agglomerative and divisive hierarchical clustering
What is Deep learning?
It can be understood as a set of algorithms that were developed to train artificial neural networks with many layers most efficiently.
What does the feedforward in feedforward artificial neural network mean?
Feedforward refers to the fact that each layer serves as the input to the next layer without loops, in contrast to recurrent neural networks for example.
What is gradient checking?
It is essentially a comparison between our analytical gradients in the network and numerical gradients, where a numerically approximated gradient =( J(w + epsilon) - J(w) ) / epsilon, for example.
What are Recurrent Neural Networks?
Recurrent Neural Networks (RNNs) can be thought of as feedforward neural networks with feedback loops or backpropagation through time. In RNNs, the neurons only fire for a limited amount of time before they are (temporarily) deactivated. In turn, these neurons activate other neurons that fire at a later point in time. Basically, we can think of recurrent neural networks as MLPs with an additional time variable. The time component and dynamic structure allows the network to use not only the current inputs but also the inputs that it encountered earlier.
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
Explain what is Machine learning?
Machine learning is the field of study that gives computers the avility to learn without being explicitly programmed.
OR
The acquisition of knowledge or skills through study or experience by a machine.
OR
The ability for machines to learn without being explicitly programmed.

What are different types of learning?
- Supervised learning

- Unsupervised learning

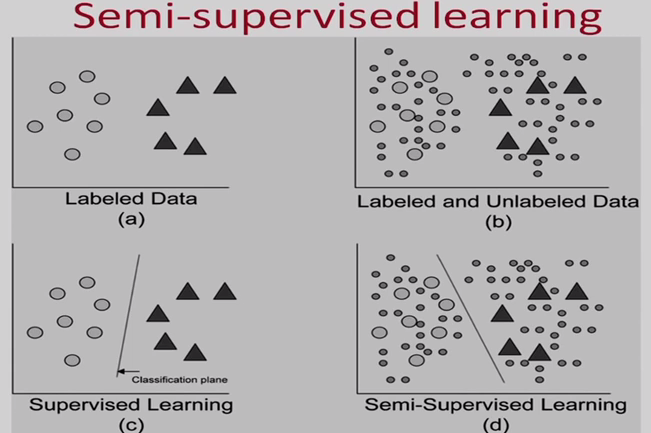
- Semisupervised learning
- Reinforcement learning
- Transduction
- Learning to Learn
Artificial Intelligence: artificial intelligence. As the name implies, it means to produce intelligence in artificial ways, in other words, using computers.


Machine Learning: This is a sub-topic of AI. As learning is one of the many functionalities of an intelligent system, machine learning is one of the many functionalities in an AI.
Deep learning: Deep learning is the specific sub-field in machine learning involving making very large and deep (i.e. many layers of neurons) neural networks to solve specific problems. It is the current “model of choice” for many machine learning applications.
What are some popular algorithms of Machine Learning?
Decision Trees
Neural Networks (back propagation)
Probabilistic networks
Nearest Neighbor
Support vector machines(SVM)
What are the three most important components of every machine learning algorithm?
Representation: How to represent knowledge. Examples include decision trees, sets of rules, instances, graphical models, neural networks, support vector machines, model ensembles and others.
Evaluation: The way to evaluate candidate programs (hypotheses). Examples include accuracy, prediction and recall, squared error, likelihood, posterior probability, cost, margin, entropy k-L divergence and others.
Optimization: The way candidate programs are generated known as the search process. For example combinatorial optimization, convex optimization, constrained optimization.
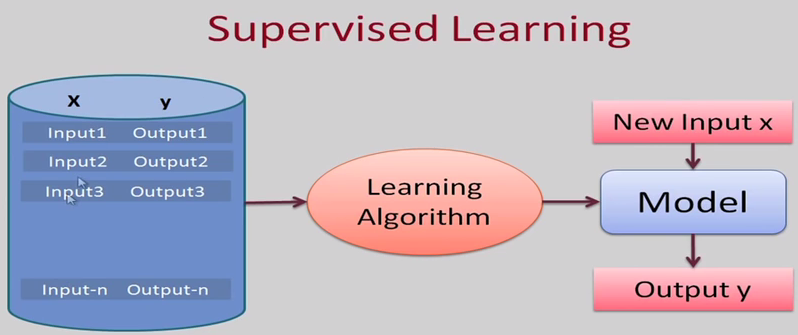
Explain Supervised learing?
In unsupervised learning we only have xi values, and also have explicit target labels.
Explain Unsupervised learing?
In unsupervised learning we only have xi values, but no explicit target labels.
Difference between Supervised and Unsupervised learning?
What type of algorithm used in Supervised and Unsupervised learning?

Explain classification?
In machine learning, classification is the problem of identifying to which of a set of categories (sub-populations) a new observation belongs, on the basis of a training set of data containing observations (or instances) whose category membership is known.
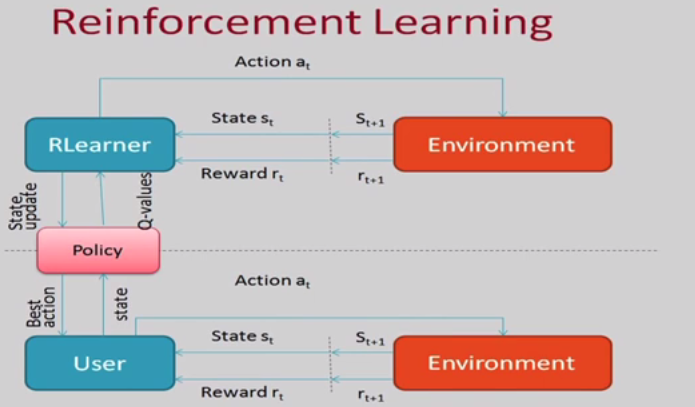
What is reinforcement Learning?
The goal is to develop a system (agent) that improves its performance based on interactions with the environment. Since the information about the current state of the environment typically also includes a so-called reward signal, we can think of reinforcement learning as a field related to supervised learning. However, in reinforcement learning this feedback is not the correct ground truth label or value, but a measure of how well the action was measured by a reward function. Through the interaction with the environment, an agent can then use reinforcement learning to learn a series of actions that maximizes this reward via an exploratory trial-and-error approach or deliberative planning. A popular example of reinforcement learning is a chess engine.
Describe the relationship between all types of machine learning and particularly the application of unsupervised.
In supervised learning, we know the right answer beforehand when we train our model, and in reinforcement learning, we define a measure of reward for particular actions by the agent. In unsupervised learning, however, we are dealing with unlabeled data or data of unknown structure. Using unsupervised learning techniques, we are able to explore the structure of our data to extract meaningful information without the guidance of a known outcome variable or reward function.
What do you understand by Cost Function in supervised learning problem? How it help you?
Cost function takes an average difference of all the results of the hypothesis with inputs from x's and the actual output y's. and help to figure best straight line to our data.

What is a support vector machine?
Maximize the minimum distance of all errors.
e.g.
The dish is good by itself but to enhance the dish, you put the most amount of salt in a dish without it tasting too salty
What do we call a learning problem, if the target variable is continuous?
When the target variable that we're trying to predict is continuous, the learning problem is also called a regression problem.
What do we call a learning problem, if the target variable can take on only a small number of values?
When y can take on only a small number of discrete values, the learning problem is also called a classification problem.
Explain classifiers?

What do you understand by hypothesis space?
It is a set of legal hypothesis.

How do we measure the accuracy of a hypothesis function?
We measure the accuracy by using a cost function, usually denoted by J.
Describe variance and bias in what they measure?
Variance measures the consistency (or variability) of the model prediction for a particular sample instance if we would retrain the model multiple times, for example, on different subsets of the training dataset. We can say that the model is sensitive to the randomness in the training data. In contrast, bias measures how far off the predictions are from the correct values in general if we rebuild the model multiple times on different training datasets, bias is the measure of the systematic error that is not due to randomness.
Describe the benefits of regularization?
One way of finding a good bias-variance tradeoff is to tune the complexity of the model via regularization. Regularization is a very useful method to handle collinearity (high correlation among features), filter out noise from data, and eventually prevent overfitting. The concept behind regularization is to introduce additional information (bias) to penalize extreme parameter weights.
Explain Random forest?
Random forest is a collection of trees, hence the name 'forest'! Each tree is built from a sample of the data. The output of a RF is the model of the classes (for classification) or the mean prediction (for regression) of the individual trees.
What are training algorithms in Machine learning?
Training algorithms gives a model h with Solution Space S and a training set {X,Y}, a learning algorithm finds the solution that minimizes the cost function J(S)
Explain Training and Testing phase in Machine learning?

Explain Local minima?
The smallest value of the function. But it might not be the only one.
What is multivariate linear regression?
Linear regression with multiple variables.
How can we speed up gradient descent?
We can speed up gradient descent by having each of our input values in roughly the same range.
What is the decision boundary given a logistic function?
The decision boundary is the line that separates the area where y = 0 and where y = 1. It is created by our hypothesis function.
What is underfitting? p
Underfitting, or high bias, is when the form of our hypothesis function h maps poorly to the trend of the data.
What usually causes underfitting?
It is usually caused by a function that is too simple or uses too few features.
What is overfitting? p
Overfitting, or high variance, is caused by a hypothesis function that fits the available data but does not generalize well to predict new data.
What usually causes overfitting?
It is usually caused by a complicated function that creates a lot of unnecessary curves and angles unrelated to the data.
How can we avoid overfitting?
Stop growing when data split is no more statistically significant OR grow tree & post-prune.
What is features scaling?
Feature scaling is a method used to standardize the range of independent variables or features of data. In data processing, it is also known as data normalization and is generally performed during the data preprocessing step.
What are the advantages of data normalization?
Few advantages of normalizing the data are as follows:
1. It makes your training faster.
2. It prevents you from getting stuck in local optima.
3. It gives you a better error surface shape.
4. Wweight decay and bayes optimization can be done more conveniently.
What range is used for feature scaling
0-1
What is the formula for feature scaling?
(x-xmin)/(xmax-xmin)
What two algorithms does features scaling help with?
K-means and SVM RBF Kernal
What two algorithms does features scaling NOT help with?
Linear regression and decision trees
What do you understand by clustering?
Clustering means grouping of data or dividing a large data set into smaller data sets of some similarity.
What is a good clustering algorithm?
K-means
In a basic sense, what are neurons?
Neurons are basically computational units that take inputs, called dendrites, as electrical inputs, called "spikes", that are channeled to outputs , called axons.
What is a neural network?
Takes an input layer -> hidden layer of logistic regression -> outputs of the hidden layer are binary that go to the output layer
e.g.
is that a house cat? input layer is whiskers, fur, paws, large. Hidden layer finds that cats are small (so the output of the hidden layer is 1, 1, 1 ,0). Because not all features (outputs) from the hidden layers are true, it's not a house cat.
What is Regression Analysis?
We are given a number of predictor (explanatory) variables and a continuous response variable (outcome), and we try to find a relationship between those variables that allows us to predict an outcome.
What are the dendrites in the model of neural networks?
In our model, our dendrites are like the input features.
What are the axons in the model of neural networks?
In our model, the axons are the results of our hypothesis function.
What is the bias unit of a neural network?
The input node x0 is sometimes called the "bias unit." It is always equal to 1.
What are the weights of a neural network?
Using the logistic function, our "theta" parameters are sometimes called "weights".
What is the activation function of a neural network?
The logistic function (as in classification) is also called a sigmoid (logistic) activation function.
How do we label the hidden layers of a neural network?
We label these intermediate or hidden layer nodes. The nodes are also called activation units.
What is the kernal method?
When you can't use logistical regression because there isn't a clear delineation between the two groups, you need to draw a curved line. Multiply x & y to separate groups on a 3d plane.
e.g.
monkey in the middle. If there are two people on either side of the person in the middle, how do you draw a straight line to separate the two groups (e.g. logistical regression)? You can't. You have to draw a curved line.
What's the motivation for the kernel trick?
To solve a nonlinear problem using an SVM, we transform the training data onto a higher dimensional feature space via a mapping function and train a linear SVM model to classify the data in this new feature space. Then we can use the same mapping function. to transform new, unseen data to classify it using the linear SVM model.
However, one problem with this mapping approach is that the construction of the new features is computationally very expensive, especially if we are dealing with high-dimensional data. This is where the so-called kernel trick comes into play
Give the setup of using a neural network.
• Pick a network architecture.
• Choose the layout of your neural network.
• Number of input units; dimension of features x i.
• Number of output units; number of classes.
• Number of hidden units per layer; usually more the better.
How does one train a neural network?
1. Randomly initialize the weights.
2. Implement forward propagation.
3. Implement the cost function.
4. Implement backpropagation.
5. Use gradient checking to confirm that your backpropagation works.
6. Use gradient descent to minimize the cost function with the weights in theta.
How can we break down our decision process deciding what to do next?
• Getting more training examples: Fixes high variance.
• Trying smaller sets of features: Fixes high variance.
• Adding features: Fixes high bias.
• Adding polynomial features: Fixes high bias.
• Decreasing lambda: Fixes high bias.
• Increasing lambda: Fixes high variance.
What issue poses a neural network with fewer parameters?
A neural network with fewer parameters is prone to underfitting.
What issue poses a neural network with more parameters?
A large neural network with more parameters is prone to overfitting.
What is the relationship between the degree of the polynomial d and the underfitting or overfitting of our hypothesis?
• High bias (underfitting): both J train(Θ) and J CV(Θ) will be high. Also, J CV(Θ) is approximately equal to J train(Θ).
• High variance (overfitting): J train(Θ) will be low and J CV(Θ) will be much greater than J train(Θ).
Describe Logistic Regression vs SVM.
In practical classification tasks, linear logistic regression and linear SVMs often yield very similar results. Logistic regression tries to maximize the conditional likelihoods of the training data, which makes it more prone to outliers than SVMs. The SVMs mostly care about the points that are closest to the decision boundary (support vectors). On the other hand, logistic regression has the advantage that it is a simpler model that can be implemented more easily. Furthermore, logistic regression models can be easily updated, which is attractive when working with streaming data.
Give an overview of the decision tree process.
We start at the tree root and split the data on the feature that results in the largest information gain (IG). In an iterative process, we can then repeat this splitting procedure at each child node until the leaves are pure. This means that the samples at each node all belong to the same class.
Describe parametric vs nonparametric models?
Machine learning algorithms can be grouped into parametric and nonparametric models. Using parametric models, we estimate parameters from the training dataset to learn a function that can classify new data points without requiring the original training dataset anymore. Typical examples of parametric models are the perceptron, logistic regression, and the linear SVM. In contrast, nonparametric models can't be characterized by a fixed set of parameters, and the number of parameters grows with the training data. Two examples of nonparametric models that we have seen so far are the decision tree classifier/random forest and the kernel SVM.
What is feature extraction?
A method to transform or project the data onto a new feature space. In the context of dimensionality reduction, feature extraction can be understood as an approach to data compression with the goal of maintaining most of the relevant information.
Explain PCA in a nutshell.
It aims to find the directions of maximum variance in high-dimensional data and projects it onto a new subspace with equal or fewer dimensions that the original one. The orthogonal axes (principal components) of the new subspace can be interpreted as the directions of maximum variance given the constraint that the new feature axes are orthogonal to each other
What is Exploratory Data Analysis?
(EDA) is an important and recommended first step prior to the training of a machine learning model. For example, it may help us to visually detect the presence of outliers, the distribution of the data, and the relationships between features.
What is word stemming?
The process of transforming a word into its root form that allows us to map related words to the same stem
What is OLS?
Ordinary Least Squares (OLS) method is to estimate the parameters of the regression line that minimizes the sum of the squared vertical distances (residuals or errors) to the sample points.
What are residual plots?
Since our model uses multiple explanatory variables, we can't visualize the linear regression line (or hyperplane to be precise) in a two-dimensional plot, but we can plot the residuals (the differences or vertical distances between the actual and predicted values) versus the predicted values to diagnose our regression model. Those residual plots are a commonly used graphical analysis for diagnosing regression models to detect non-linearity and outliers, and to check if the errors are randomly distributed.
What is the elbow method?
A graphical technique to estimate the optimal number of clusters k for a given task. Intuitively, we can say that, if k increases, the distortion (within-cluster SSE) will decrease. This is because the samples will be closer to the centroids they are assigned to. The idea behind the elbow method is to identify the value of k where the distortion begins to increase most rapidly,
The two main approaches to hierarchical clustering are?
Agglomerative and divisive hierarchical clustering
What is Deep learning?
It can be understood as a set of algorithms that were developed to train artificial neural networks with many layers most efficiently.
What does the feedforward in feedforward artificial neural network mean?
Feedforward refers to the fact that each layer serves as the input to the next layer without loops, in contrast to recurrent neural networks for example.
What is gradient checking?
It is essentially a comparison between our analytical gradients in the network and numerical gradients, where a numerically approximated gradient =( J(w + epsilon) - J(w) ) / epsilon, for example.
What are Recurrent Neural Networks?
Recurrent Neural Networks (RNNs) can be thought of as feedforward neural networks with feedback loops or backpropagation through time. In RNNs, the neurons only fire for a limited amount of time before they are (temporarily) deactivated. In turn, these neurons activate other neurons that fire at a later point in time. Basically, we can think of recurrent neural networks as MLPs with an additional time variable. The time component and dynamic structure allows the network to use not only the current inputs but also the inputs that it encountered earlier.


Comments